Multiple samples#
In this notebook, we will work with multiple samples, and discuss batch effect issues.
Load packages#
import scanpy as sc
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import scipy
import seaborn as sns
Loading multiple samples into Scanpy#
All of the computation we have done so far has been on a single sample. However, most real world data are likely not going to be a single sample and often require us to merge multiple data. We will use Scanpy to concatenate multiple data into one unified anndata object and discuss the issue of technical effect and its correction.
For the purposes of illustration we will use the PBMC data (dataset 5) used in this publication: https://genomebiology.biomedcentral.com/articles/10.1186/s13059-019-1850-9. The authors provide the data in an easily usable format (JinmiaoChenLab/Batch-effect-removal-benchmarking).
input_path = '/Users/sara.jimenez/Documents/scWorkshop/data/'
batch-1#
data_batch1 = pd.read_csv(input_path + 'b1_exprs.txt', sep = '\t', index_col = 0)
celltype_batch1 = pd.read_csv(input_path + 'b1_celltype.txt', sep = '\t', index_col = 0)
data_batch1.head()
| data_3p-AAACCTGAGCATCATC-0 | data_3p-AAACCTGAGCTAGTGG-0 | data_3p-AAACCTGCACATTAGC-0 | data_3p-AAACCTGCACTGTTAG-0 | data_3p-AAACCTGCATAGTAAG-0 | data_3p-AAACCTGCATGAACCT-0 | data_3p-AAACCTGGTAAGAGGA-0 | data_3p-AAACCTGGTAGAAGGA-0 | data_3p-AAACCTGGTCCAGTGC-0 | data_3p-AAACCTGGTGTCTGAT-0 | ... | data_3p-TTTGTCACAGGGATTG-0 | data_3p-TTTGTCAGTAGCAAAT-0 | data_3p-TTTGTCAGTCAGATAA-0 | data_3p-TTTGTCAGTCGCGTGT-0 | data_3p-TTTGTCAGTTACCGAT-0 | data_3p-TTTGTCATCATGTCCC-0 | data_3p-TTTGTCATCCGATATG-0 | data_3p-TTTGTCATCGTCTGAA-0 | data_3p-TTTGTCATCTCGAGTA-0 | data_3p-TTTGTCATCTGCTTGC-0 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RP11-34P13.3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| FAM138A | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| OR4F5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| RP11-34P13.7 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| RP11-34P13.8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
5 rows × 8098 columns
We see above that the rows are genes and the columns are cells. We will have to keep this in mind when we create an anndata object out of the data.
Let’s create an anndata object for batch1:
# Notes:
# We transpose the data to ensure rows are cells and columns are genes
# We consider columns of the dataframe above as the cell names
# We consider rows of the dataframe above as the gene names
adata1 = sc.AnnData(data_batch1.values.T,
obs = pd.DataFrame(index = data_batch1.columns),
var = pd.DataFrame(index = data_batch1.index))
/var/folders/my/xsqd7w190lg06fx4rlnfklshlvq6xm/T/ipykernel_62198/428804876.py:5: FutureWarning: X.dtype being converted to np.float32 from int64. In the next version of anndata (0.9) conversion will not be automatic. Pass dtype explicitly to avoid this warning. Pass `AnnData(X, dtype=X.dtype, ...)` to get the future behavour.
adata1 = sc.AnnData(data_batch1.values.T,
adata1
AnnData object with n_obs × n_vars = 8098 × 33694
Add the author provided celltype information:
celltype_batch1
| Sample | n_counts | n_genes | batch | louvain | anno | Method | CellType | |
|---|---|---|---|---|---|---|---|---|
| data_3p-AAACCTGAGCATCATC-0 | data_3p | 2394 | 871 | 0 | 9 | B cell | 10X_3prime | B cell |
| data_3p-AAACCTGAGCTAGTGG-0 | data_3p | 4520 | 1316 | 0 | 5 | CD4 T cell | 10X_3prime | CD4 T cell |
| data_3p-AAACCTGCACATTAGC-0 | data_3p | 2788 | 898 | 0 | 1 | CD4 T cell | 10X_3prime | CD4 T cell |
| data_3p-AAACCTGCACTGTTAG-0 | data_3p | 4667 | 1526 | 0 | 0 | Monocyte_CD14 | 10X_3prime | Monocyte_CD14 |
| data_3p-AAACCTGCATAGTAAG-0 | data_3p | 4440 | 1495 | 0 | 0 | Monocyte_CD14 | 10X_3prime | Monocyte_CD14 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| data_3p-TTTGTCATCATGTCCC-0 | data_3p | 3141 | 1176 | 0 | 4 | CD8 T cell | 10X_3prime | CD8 T cell |
| data_3p-TTTGTCATCCGATATG-0 | data_3p | 5401 | 1379 | 0 | 4 | CD8 T cell | 10X_3prime | CD8 T cell |
| data_3p-TTTGTCATCGTCTGAA-0 | data_3p | 6081 | 1802 | 0 | 0 | Monocyte_CD14 | 10X_3prime | Monocyte_CD14 |
| data_3p-TTTGTCATCTCGAGTA-0 | data_3p | 3970 | 1317 | 0 | 7 | CD8 T cell | 10X_3prime | CD8 T cell |
| data_3p-TTTGTCATCTGCTTGC-0 | data_3p | 4027 | 1259 | 0 | 4 | CD8 T cell | 10X_3prime | CD8 T cell |
8098 rows × 8 columns
for item in celltype_batch1.columns:
adata1.obs[item] = celltype_batch1.loc[adata1.obs_names][item]
adata1
AnnData object with n_obs × n_vars = 8098 × 33694
obs: 'Sample', 'n_counts', 'n_genes', 'batch', 'louvain', 'anno', 'Method', 'CellType'
batch-2#
data_batch2 = pd.read_csv(input_path + 'b2_exprs.txt', sep = '\t', index_col = 0)
celltype_batch2 = pd.read_csv(input_path + 'b2_celltype.txt', sep = '\t', index_col = 0)
data_batch2.head()
| data_5p-AAACCTGAGCGATAGC-1 | data_5p-AAACCTGAGCTAAACA-1 | data_5p-AAACCTGAGGGAGTAA-1 | data_5p-AAACCTGAGTCTTGCA-1 | data_5p-AAACCTGAGTTCGATC-1 | data_5p-AAACCTGCACACTGCG-1 | data_5p-AAACCTGCACGGTGTC-1 | data_5p-AAACCTGCAGATGGGT-1 | data_5p-AAACCTGCAGGTGGAT-1 | data_5p-AAACCTGGTAAGCACG-1 | ... | data_5p-TTTGTCACAGCTGGCT-1 | data_5p-TTTGTCACAGGTGGAT-1 | data_5p-TTTGTCAGTCCGAAGA-1 | data_5p-TTTGTCAGTTGATTGC-1 | data_5p-TTTGTCATCACAAACC-1 | data_5p-TTTGTCATCCACGTTC-1 | data_5p-TTTGTCATCGCGTAGC-1 | data_5p-TTTGTCATCTTAACCT-1 | data_5p-TTTGTCATCTTACCGC-1 | data_5p-TTTGTCATCTTGTTTG-1 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RP11-34P13.3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| FAM138A | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| OR4F5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| RP11-34P13.7 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| RP11-34P13.8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
5 rows × 7378 columns
Similar to batch-1, we see above that the rows are genes and the columns are cells. We will have to keep this in mind when we create an anndata object out of the data.
Let’s create an anndata object for batch-2:
# Notes:
# We transpose the data to ensure rows are cells and columns are genes
# We consider columns of the dataframe above as the cell names
# We consider rows of the dataframe above as the gene names
adata2 = sc.AnnData(data_batch2.values.T,
obs = pd.DataFrame(index = data_batch2.columns),
var = pd.DataFrame(index = data_batch2.index))
/var/folders/my/xsqd7w190lg06fx4rlnfklshlvq6xm/T/ipykernel_62198/4161174250.py:5: FutureWarning: X.dtype being converted to np.float32 from int64. In the next version of anndata (0.9) conversion will not be automatic. Pass dtype explicitly to avoid this warning. Pass `AnnData(X, dtype=X.dtype, ...)` to get the future behavour.
adata2 = sc.AnnData(data_batch2.values.T,
adata2
AnnData object with n_obs × n_vars = 7378 × 33694
Add the author provided celltype information:
celltype_batch2
| Sample | n_counts | n_genes | batch | louvain | anno | Method | CellType | |
|---|---|---|---|---|---|---|---|---|
| data_5p-AAACCTGAGCGATAGC-1 | data_5p | 2712 | 1318 | 1 | 18 | NK cell | 10X_5prime | NK cell |
| data_5p-AAACCTGAGCTAAACA-1 | data_5p | 6561 | 2164 | 1 | 3 | Monocyte_CD14 | 10X_5prime | Monocyte_CD14 |
| data_5p-AAACCTGAGGGAGTAA-1 | data_5p | 6322 | 2112 | 1 | 8 | Monocyte_CD14 | 10X_5prime | Monocyte_CD14 |
| data_5p-AAACCTGAGTCTTGCA-1 | data_5p | 4528 | 1526 | 1 | 16 | CD8 T cell | 10X_5prime | CD8 T cell |
| data_5p-AAACCTGAGTTCGATC-1 | data_5p | 3426 | 1332 | 1 | 3 | Monocyte_CD14 | 10X_5prime | Monocyte_CD14 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| data_5p-TTTGTCATCCACGTTC-1 | data_5p | 6547 | 2044 | 1 | 3 | Monocyte_CD14 | 10X_5prime | Monocyte_CD14 |
| data_5p-TTTGTCATCGCGTAGC-1 | data_5p | 3615 | 1397 | 1 | 10 | B cell | 10X_5prime | B cell |
| data_5p-TTTGTCATCTTAACCT-1 | data_5p | 3828 | 1480 | 1 | 16 | CD8 T cell | 10X_5prime | CD8 T cell |
| data_5p-TTTGTCATCTTACCGC-1 | data_5p | 6444 | 2388 | 1 | 28 | Plasmacytoid dendritic cell | 10X_5prime | Plasmacytoid dendritic cell |
| data_5p-TTTGTCATCTTGTTTG-1 | data_5p | 4457 | 1662 | 1 | 11 | CD8 T cell | 10X_5prime | CD8 T cell |
7378 rows × 8 columns
for item in celltype_batch2.columns:
adata2.obs[item] = celltype_batch2.loc[adata2.obs_names][item]
adata2
AnnData object with n_obs × n_vars = 7378 × 33694
obs: 'Sample', 'n_counts', 'n_genes', 'batch', 'louvain', 'anno', 'Method', 'CellType'
Concatenate#
Now that we have loaded data from both the batches, we can combine them to create one anndata object.
For details on the parameters used for the function below, please see: https://anndata.readthedocs.io/en/latest/generated/anndata.concat.html
For discussion/examples of concatenation, please see: https://anndata.readthedocs.io/en/latest/concatenation.html
Special Note: Please pay attention to join = 'outer' parameter. We are choosing to consider any gene that is expressed in either of the data. This means there may be some genes that are expressed in one data set but not in the other. What expression counts do these genes get in cells where they are not expressed? It depends on the input data matrix: if it is in sparse format they get 0, else NaN. So to ensure no NaN, we set fill_value = 0.
import anndata
adata = anndata.concat([adata1, adata2],
axis = 0,
join='outer',
label='batch_id',
index_unique='-',
fill_value=0)
# If you have more than 2 samples:
#adata = adata1_corr.concatenate(adata2_corr, adata3_corr, adata4_corr,
# axis = 0,
# join='outer',
# label='batch_id',
# index_unique='-',
# fill_value=0)
adata
AnnData object with n_obs × n_vars = 15476 × 33694
obs: 'Sample', 'n_counts', 'n_genes', 'batch', 'louvain', 'anno', 'Method', 'CellType', 'batch_id'
Below we see the .obs['batch_id'] of the adata and see that the first batch is called “0” and the second batch is called “1”.
adata.obs['batch_id']
data_3p-AAACCTGAGCATCATC-0-0 0
data_3p-AAACCTGAGCTAGTGG-0-0 0
data_3p-AAACCTGCACATTAGC-0-0 0
data_3p-AAACCTGCACTGTTAG-0-0 0
data_3p-AAACCTGCATAGTAAG-0-0 0
..
data_5p-TTTGTCATCCACGTTC-1-1 1
data_5p-TTTGTCATCGCGTAGC-1-1 1
data_5p-TTTGTCATCTTAACCT-1-1 1
data_5p-TTTGTCATCTTACCGC-1-1 1
data_5p-TTTGTCATCTTGTTTG-1-1 1
Name: batch_id, Length: 15476, dtype: category
Categories (2, object): ['0', '1']
adata.X
array([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]], dtype=float32)
# check for NaN:
np.sum(np.isnan(adata.X))
0
As seen above, there are no NaN in the combined data, so we can proceed normally.
Basic QC and normalization#
sc.pp.calculate_qc_metrics(adata, inplace = True)
# Distribution of library size (total counts); number of genes per cell
fig = plt.figure(figsize = (8*2, 6*1))
ax = fig.add_subplot(1, 2, 1)
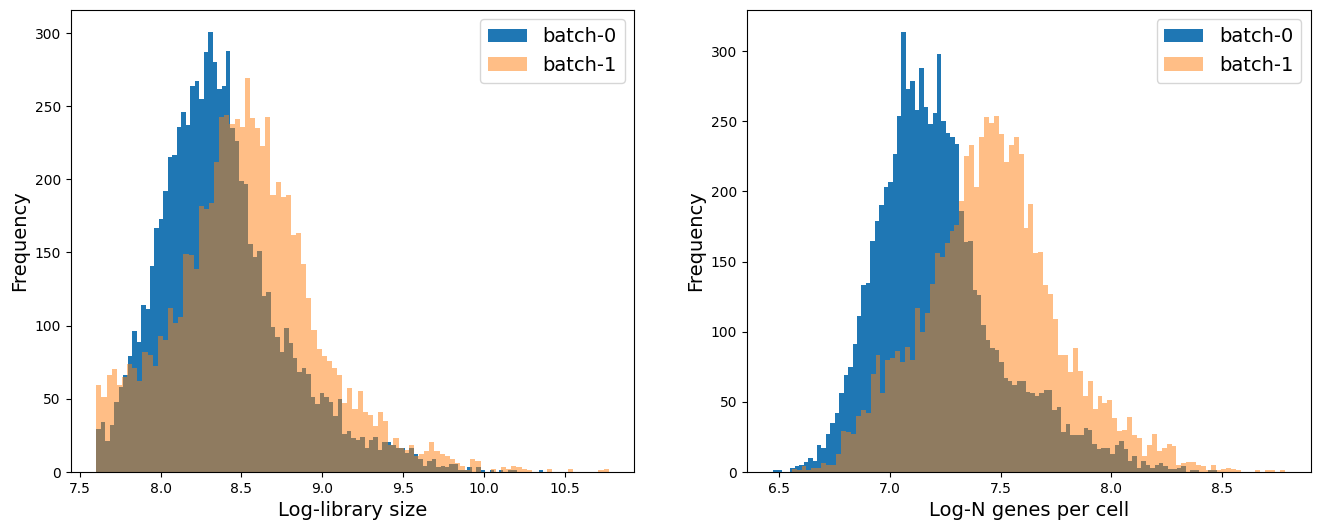
ax.hist(adata.obs['log1p_total_counts'][adata.obs['batch_id'] == '0'], 100, label = 'batch-0')
ax.hist(adata.obs['log1p_total_counts'][adata.obs['batch_id'] == '1'], 100, label = 'batch-1', alpha = 0.5)
ax.set_xlabel('Log-library size', fontsize = 14)
ax.set_ylabel('Frequency', fontsize = 14)
ax.legend(fontsize = 14)
ax = fig.add_subplot(1, 2, 2)
ax.hist(adata.obs['log1p_n_genes_by_counts'][adata.obs['batch_id'] == '0'], 100, label = 'batch-0')
ax.hist(adata.obs['log1p_n_genes_by_counts'][adata.obs['batch_id'] == '1'], 100, label = 'batch-1', alpha = 0.5)
ax.set_xlabel('Log-N genes per cell', fontsize = 14)
ax.set_ylabel('Frequency', fontsize = 14)
ax.legend(fontsize = 14)
<matplotlib.legend.Legend at 0x2d0227490>
If you have more than 2 batch, you can run a for loop to visualize the distribution of each batch compared to the whole data. For this, you can adapt the following example code:
# Distribution of library size (total counts)
fig = plt.figure(figsize = (8*2, 6*1))
for j, item in enumerate(np.unique(adata.obs['batch_id'])):
ax = fig.add_subplot(1, 2, j+1)
ax.hist(adata.obs['log1p_total_counts'], 100, label = 'All cells')
ax.hist(adata.obs['log1p_total_counts'][adata.obs['batch_id'] == item], 100, label = 'batch-' + item,
alpha = 0.5)
ax.set_xlabel('Log-library size', fontsize = 14)
ax.set_ylabel('Frequency', fontsize = 14)
ax.legend(fontsize = 14)
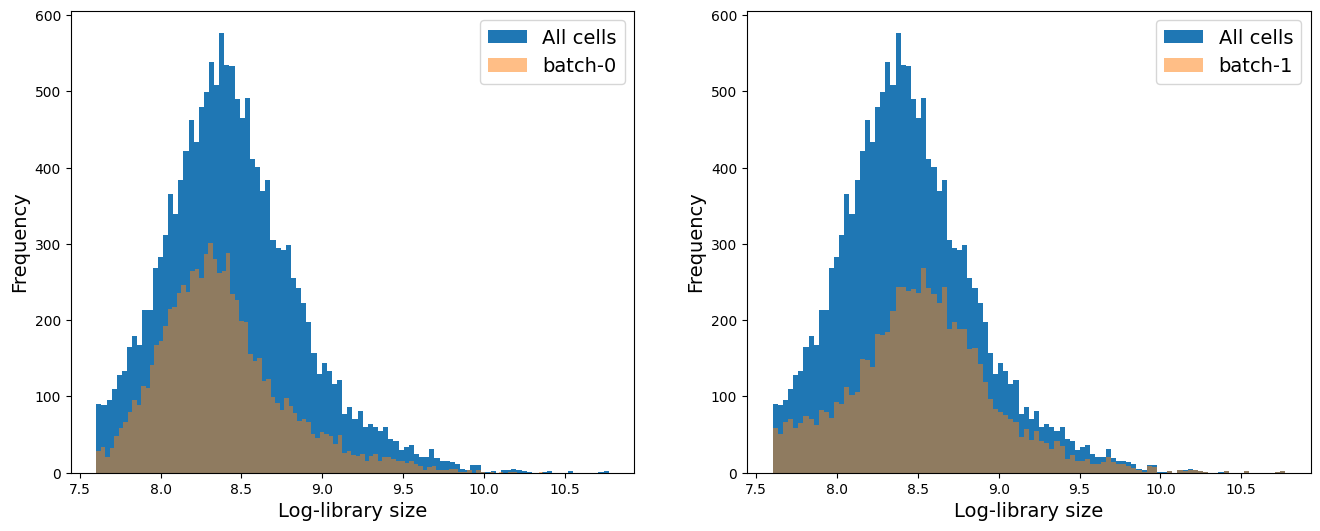
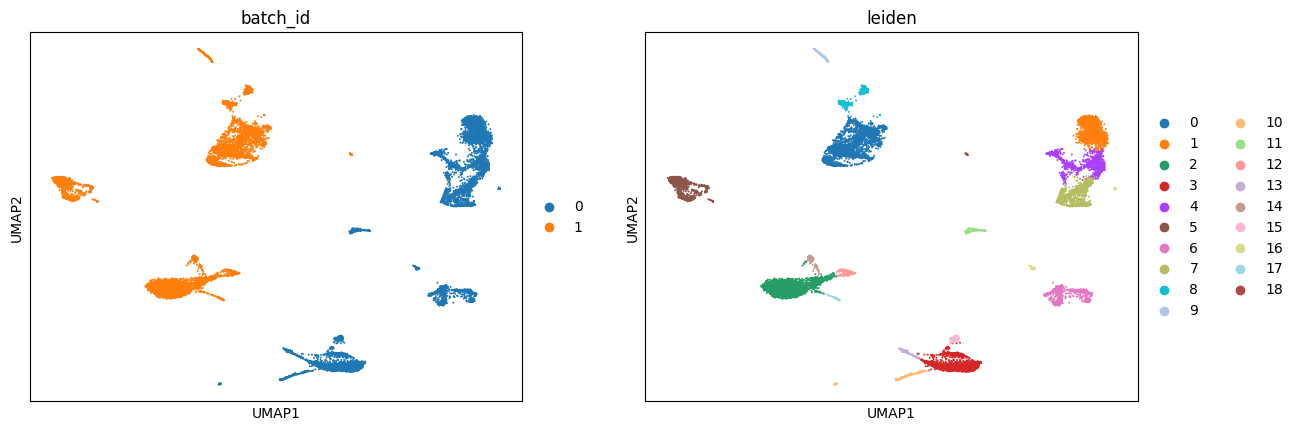
We see that on average batch-1 cells have higher library size and higher number of genes expressed per cell. We will keep this mind as we analyze the data.
# Distribution of number of genes a cell is expressed in
fig = plt.figure(figsize = (8*2, 6*1))
ax = fig.add_subplot(1, 2, 1)
ax.hist(np.log2(adata.var['n_cells_by_counts'] + 1), 100)
ax.set_xlabel('Log-N cells per gene', fontsize = 14)
ax.set_ylabel('Frequency', fontsize = 14)
ax = fig.add_subplot(1, 2, 2)
ax.hist(np.log2(adata.var['n_cells_by_counts'] + 1), 100)
ax.set_xlabel('Log-N cells per gene', fontsize = 14)
ax.set_ylabel('Frequency, trimmed axis', fontsize = 14)
ax.set_ylim([0, 500])
(0.0, 500.0)
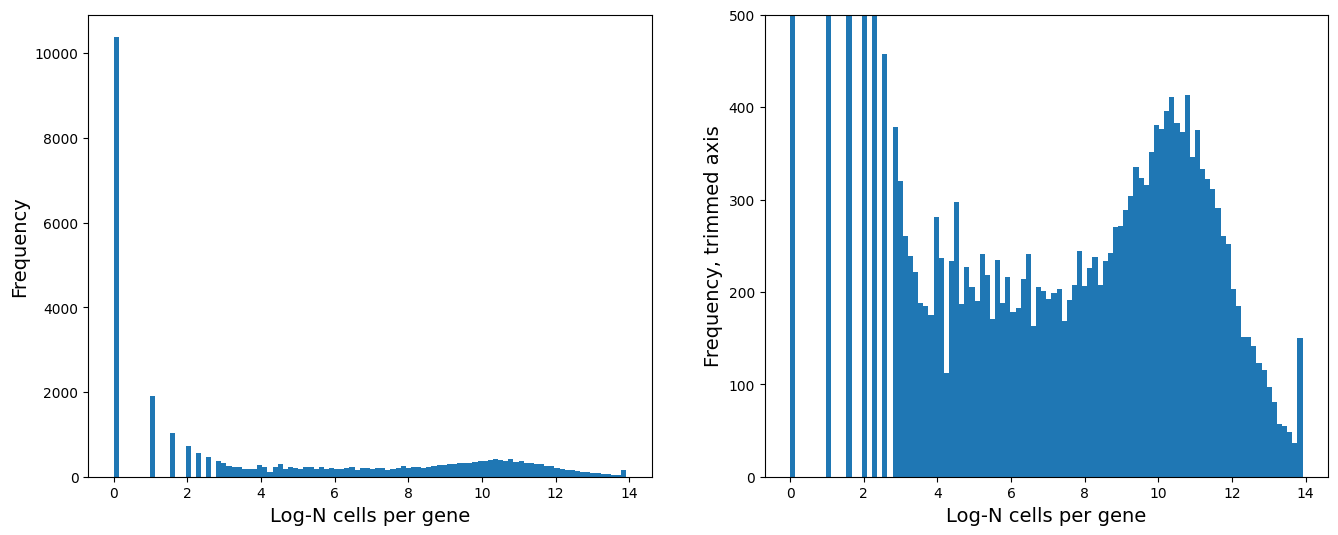
# Remove genes expressed in less than 64 cells:
sc.pp.filter_genes(adata, min_cells=2**6)
adata
AnnData object with n_obs × n_vars = 15476 × 13386
obs: 'Sample', 'n_counts', 'n_genes', 'batch', 'louvain', 'anno', 'Method', 'CellType', 'batch_id', 'n_genes_by_counts', 'log1p_n_genes_by_counts', 'total_counts', 'log1p_total_counts', 'pct_counts_in_top_50_genes', 'pct_counts_in_top_100_genes', 'pct_counts_in_top_200_genes', 'pct_counts_in_top_500_genes'
var: 'n_cells_by_counts', 'mean_counts', 'log1p_mean_counts', 'pct_dropout_by_counts', 'total_counts', 'log1p_total_counts', 'n_cells'
# Normalizing + log transformation
# Store raw counts for future
adata.layers['raw_counts'] = adata.X.copy()
# Normalize with median library size
sc.pp.normalize_total(adata, inplace = True)
# Store the normalized counts for future
adata.layers['norm_counts'] = adata.X.copy()
# Take log2 of the normalized counts
adata.X = np.log2(adata.X + 1)
adata
AnnData object with n_obs × n_vars = 15476 × 13386
obs: 'Sample', 'n_counts', 'n_genes', 'batch', 'louvain', 'anno', 'Method', 'CellType', 'batch_id', 'n_genes_by_counts', 'log1p_n_genes_by_counts', 'total_counts', 'log1p_total_counts', 'pct_counts_in_top_50_genes', 'pct_counts_in_top_100_genes', 'pct_counts_in_top_200_genes', 'pct_counts_in_top_500_genes'
var: 'n_cells_by_counts', 'mean_counts', 'log1p_mean_counts', 'pct_dropout_by_counts', 'total_counts', 'log1p_total_counts', 'n_cells'
layers: 'raw_counts', 'norm_counts'
Highly variable genes, PCA, Nearest Neighbor Graph, UMAP#
# HVG
sc.pp.highly_variable_genes(adata, n_top_genes = 4000)
adata.uns['id_hvg'] = np.where(adata.var['highly_variable'])[0]
# PCA
sc.tl.pca(adata, n_comps=100, use_highly_variable=None)
plt.plot(range(len(adata.uns['pca']['variance_ratio'])), np.cumsum(adata.uns['pca']['variance_ratio']) * 100, '.-')
plt.axvline(30, color = 'r')
plt.xlabel('Principal Component')
plt.ylabel('% Variance Explained')
Text(0, 0.5, '% Variance Explained')
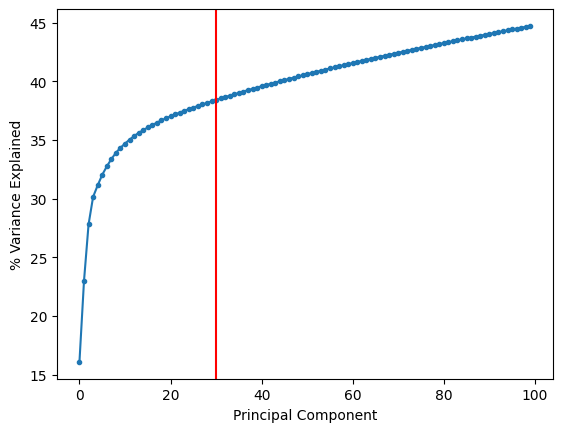
Based on the plot above, we will select 30 principal components.
adata.obsm['X_pca'] = adata.obsm['X_pca'][:, 0:30]
# Nearest neighbors on PCA
sc.pp.neighbors(adata, n_neighbors=30, use_rep='X_pca', metric='euclidean', key_added='neighbors_30')
/Users/sara.jimenez/miniconda3/envs/scvi-env/lib/python3.9/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
OMP: Info #276: omp_set_nested routine deprecated, please use omp_set_max_active_levels instead.
# UMAP using the nearest neighbors
sc.tl.umap(adata, neighbors_key = 'neighbors_30', min_dist=0.1)
# Clustering using leiden
sc.tl.leiden(adata, resolution = 0.5, neighbors_key = 'neighbors_30')
adata
AnnData object with n_obs × n_vars = 15476 × 13386
obs: 'Sample', 'n_counts', 'n_genes', 'batch', 'louvain', 'anno', 'Method', 'CellType', 'batch_id', 'n_genes_by_counts', 'log1p_n_genes_by_counts', 'total_counts', 'log1p_total_counts', 'pct_counts_in_top_50_genes', 'pct_counts_in_top_100_genes', 'pct_counts_in_top_200_genes', 'pct_counts_in_top_500_genes', 'leiden'
var: 'n_cells_by_counts', 'mean_counts', 'log1p_mean_counts', 'pct_dropout_by_counts', 'total_counts', 'log1p_total_counts', 'n_cells', 'highly_variable', 'means', 'dispersions', 'dispersions_norm'
uns: 'hvg', 'id_hvg', 'pca', 'neighbors_30', 'umap', 'leiden'
obsm: 'X_pca', 'X_umap'
varm: 'PCs'
layers: 'raw_counts', 'norm_counts'
obsp: 'neighbors_30_distances', 'neighbors_30_connectivities'
Visualize the results#
sc.pl.umap(adata, color = ['batch_id', 'leiden'])
/Users/sara.jimenez/miniconda3/envs/scvi-env/lib/python3.9/site-packages/scanpy/plotting/_tools/scatterplots.py:392: UserWarning: No data for colormapping provided via 'c'. Parameters 'cmap' will be ignored
cax = scatter(
/Users/sara.jimenez/miniconda3/envs/scvi-env/lib/python3.9/site-packages/scanpy/plotting/_tools/scatterplots.py:392: UserWarning: No data for colormapping provided via 'c'. Parameters 'cmap' will be ignored
cax = scatter(
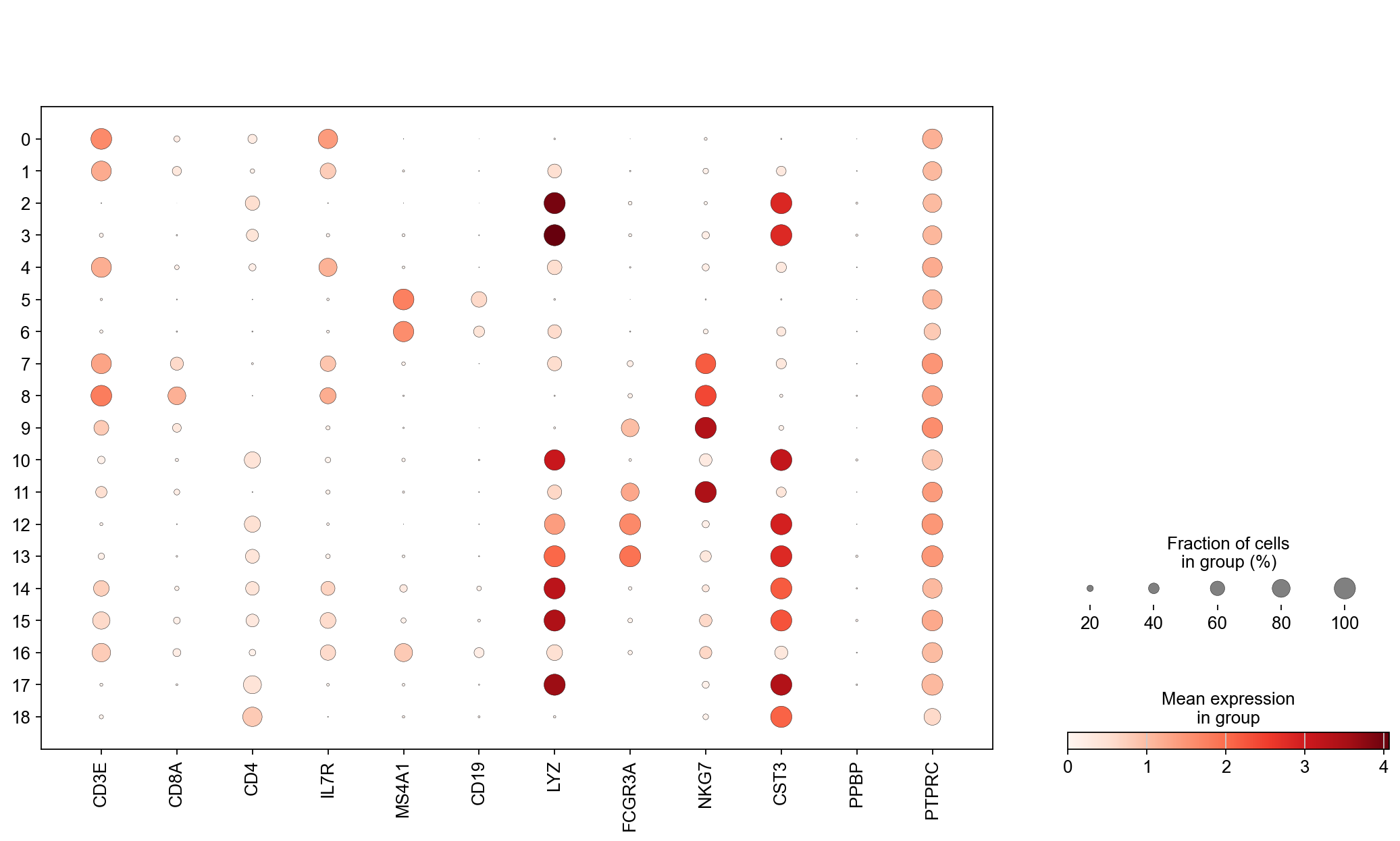
Visualize some genes#
genes = ['CD3E', 'CD8A', 'CD4', 'IL7R', 'MS4A1', 'CD19', 'LYZ', 'FCGR3A', 'NKG7', 'CST3', 'PPBP', 'PTPRC']
sc.set_figure_params(scanpy=True, fontsize = 14)
fig = plt.figure(figsize = (8*2, 6*1.5))
ax1 = fig.add_subplot(1, 1, 1)
ac = sc.pl.dotplot(adata, genes, groupby = 'leiden', log=True,
layer = 'norm_counts',
show = False, ax = ax1)
/Users/sara.jimenez/miniconda3/envs/scvi-env/lib/python3.9/site-packages/scanpy/plotting/_dotplot.py:749: UserWarning: No data for colormapping provided via 'c'. Parameters 'cmap', 'norm' will be ignored
dot_ax.scatter(x, y, **kwds)
Batch Effect Correction#
Batch effect is a technical effect that can confound biological interpretations. We mostly design experiments in such a way that there is as little batch effect as possible. But often times, we wish to compare our data at hand against some other published data. It is natural to expect some batch effect in such cases. Therefore, we need to find computational solutions to correct such technical confounder. As such, this is one of the busiest areas for computational methods development.
While there exists many methods to perform such correction, there is a common underlying assumption in all the methods: there must be some sub-populations with the same phenotype (cell type or state) across batches. Under this assumption, a majority of the methods begin by computing nearest neighbor cell or mutually nearest neighbor (MNN) between batches to identify the similar cells. While we have covered nearest neighbor cell in the previous sessions, we have not discussed mutually nearest neighbor cells. We define mutually nearest neighbor cells as follows: If a pair of cells from each batch is contained in each other’s set of nearest neighbors, those cells are considered to be mutual nearest neighbors. The methods interpret these pairs as consisting cells that belong to the same cell type or state despite being generated in different batches.
Here, we will discuss some of the most popular methods for batch effect correction.
Scanorama: brianhie/scanorama
Scanorama uses randomized singular value decomposition (SVD) - similar to PCA - to compress the gene expression profiles into a low-dimensional embedding.
It then searches for MNNs in the dimensionality reduced spaces and uses them in a careful way (weighted by similarity) to guide batch integration.
Note: Scanorama also corrects the expression of the genes in all the batches (i.e. outputs a batch corrected gene expression matrix) that can be utilized downstream for further analysis such as visualization, differential expression etc.
FastMNN:
FastMNN uses principal component analysis (PCA) to compress the gene expression profiles into a low-dimensional embedding.
It then searches for MNNs in the dimensionality reduced spaces and uses them to compute a translation vector to align the datasets into a shared space.
More details can be found here: https://marionilab.github.io/FurtherMNN2018/theory/description.html
Note: The original version is
mnnCorrect, but it is more computationally demanding in terms of CPU and memory as it uses the full high dimensional gene expression space. (https://rdrr.io/bioc/batchelor/man/mnnCorrect.html)Note: FastMNN also corrects the expression of the genes in all the batches (i.e. outputs a batch corrected gene expression matrix) that can be utilized downstream for further analysis such as visualization, differential expression etc.
Harmony: https://portals.broadinstitute.org/harmony/articles/quickstart.html
Harmony uses Principal Component Analysis (PCA) to compress the gene expression profiles into a low-dimensional embedding.
In the PCA space, Harmony iteratively removes batch effects present. At each iteration, it clusters similar cells from different batches and maximizes the diversity of batches within each cluster. It then calculates a correction factor for each cell to be applied. It is good for visualization.
Note: Harmony does not correct the expression of the genes in all the batches.
Note: Harmony has also been noted to mess up the structure of the data post-correction, so we recommend to use with caution and ensuring that biological interpretation remains consistent.
Seurat Integrate: https://satijalab.org/seurat/articles/integration_introduction.html
Seurate Integrate uses canonical correlation analysis (CCA) to compress the gene expression profiles into a low-dimensional embedding.
It then searches for MNNs in the dimensionally reduced spaces and uses them as “anchors” to guide batch correction.
Note: Seurat Integrate does not correct the expression of the genes in all the batches.
We provide example code to run four different batch correction methods.
Batch effect correction - Scanorama#
While Scanorama is integrated into Scanpy, the current implementation on Scanpy does not correct the gene expression matrix. Therefore we will use the original stand-alone implementation of Scanorama (i.e. we will not call the function via Scanpy).
!pip install scanorama
Collecting scanorama
Downloading scanorama-1.7.4-py3-none-any.whl (12 kB)
Collecting geosketch>=1.0
Downloading geosketch-1.3-py3-none-any.whl (8.1 kB)
Requirement already satisfied: scikit-learn>=0.20rc1 in /Users/sara.jimenez/miniconda3/envs/scvi-env/lib/python3.9/site-packages (from scanorama) (1.2.2)
Requirement already satisfied: matplotlib>=2.0.2 in /Users/sara.jimenez/miniconda3/envs/scvi-env/lib/python3.9/site-packages (from scanorama) (3.7.1)
Collecting intervaltree>=3.1.0
Downloading intervaltree-3.1.0.tar.gz (32 kB)
Preparing metadata (setup.py) ... ?25ldone
?25hCollecting fbpca>=1.0
Downloading fbpca-1.0.tar.gz (11 kB)
Preparing metadata (setup.py) ... ?25ldone
?25hRequirement already satisfied: annoy>=1.11.5 in /Users/sara.jimenez/miniconda3/envs/scvi-env/lib/python3.9/site-packages (from scanorama) (1.17.3)
Requirement already satisfied: scipy>=1.0.0 in /Users/sara.jimenez/miniconda3/envs/scvi-env/lib/python3.9/site-packages (from scanorama) (1.11.4)
Requirement already satisfied: numpy>=1.12.0 in /Users/sara.jimenez/miniconda3/envs/scvi-env/lib/python3.9/site-packages (from scanorama) (1.26.4)
Collecting sortedcontainers<3.0,>=2.0
Using cached sortedcontainers-2.4.0-py2.py3-none-any.whl (29 kB)
Requirement already satisfied: fonttools>=4.22.0 in /Users/sara.jimenez/miniconda3/envs/scvi-env/lib/python3.9/site-packages (from matplotlib>=2.0.2->scanorama) (4.39.4)
Requirement already satisfied: pyparsing>=2.3.1 in /Users/sara.jimenez/miniconda3/envs/scvi-env/lib/python3.9/site-packages (from matplotlib>=2.0.2->scanorama) (3.0.9)
Requirement already satisfied: cycler>=0.10 in /Users/sara.jimenez/miniconda3/envs/scvi-env/lib/python3.9/site-packages (from matplotlib>=2.0.2->scanorama) (0.11.0)
Requirement already satisfied: kiwisolver>=1.0.1 in /Users/sara.jimenez/miniconda3/envs/scvi-env/lib/python3.9/site-packages (from matplotlib>=2.0.2->scanorama) (1.4.4)
Requirement already satisfied: contourpy>=1.0.1 in /Users/sara.jimenez/miniconda3/envs/scvi-env/lib/python3.9/site-packages (from matplotlib>=2.0.2->scanorama) (1.0.7)
Requirement already satisfied: packaging>=20.0 in /Users/sara.jimenez/miniconda3/envs/scvi-env/lib/python3.9/site-packages (from matplotlib>=2.0.2->scanorama) (23.1)
Requirement already satisfied: pillow>=6.2.0 in /Users/sara.jimenez/miniconda3/envs/scvi-env/lib/python3.9/site-packages (from matplotlib>=2.0.2->scanorama) (9.5.0)
Requirement already satisfied: python-dateutil>=2.7 in /Users/sara.jimenez/miniconda3/envs/scvi-env/lib/python3.9/site-packages (from matplotlib>=2.0.2->scanorama) (2.8.2)
Requirement already satisfied: importlib-resources>=3.2.0 in /Users/sara.jimenez/miniconda3/envs/scvi-env/lib/python3.9/site-packages (from matplotlib>=2.0.2->scanorama) (5.12.0)
Requirement already satisfied: threadpoolctl>=2.0.0 in /Users/sara.jimenez/miniconda3/envs/scvi-env/lib/python3.9/site-packages (from scikit-learn>=0.20rc1->scanorama) (3.1.0)
Requirement already satisfied: joblib>=1.1.1 in /Users/sara.jimenez/miniconda3/envs/scvi-env/lib/python3.9/site-packages (from scikit-learn>=0.20rc1->scanorama) (1.2.0)
Requirement already satisfied: zipp>=3.1.0 in /Users/sara.jimenez/miniconda3/envs/scvi-env/lib/python3.9/site-packages (from importlib-resources>=3.2.0->matplotlib>=2.0.2->scanorama) (3.15.0)
Requirement already satisfied: six>=1.5 in /Users/sara.jimenez/miniconda3/envs/scvi-env/lib/python3.9/site-packages (from python-dateutil>=2.7->matplotlib>=2.0.2->scanorama) (1.16.0)
Building wheels for collected packages: fbpca, intervaltree
Building wheel for fbpca (setup.py) ... ?25ldone
?25h Created wheel for fbpca: filename=fbpca-1.0-py3-none-any.whl size=11373 sha256=8a94821a87ee66a0211e56ab18ee5926dc8a9e6b477abcedffc7962b823c79a7
Stored in directory: /Users/sara.jimenez/Library/Caches/pip/wheels/f5/60/60/28df6c25f4d22b73d1a2b1c7e4842a5e2178e35e47b62e8e9a
Building wheel for intervaltree (setup.py) ... ?25ldone
?25h Created wheel for intervaltree: filename=intervaltree-3.1.0-py2.py3-none-any.whl size=26098 sha256=17d2921060b808a31206ba813de6462470362bd69a129f9bc790d0a147fc501c
Stored in directory: /Users/sara.jimenez/Library/Caches/pip/wheels/ab/fa/1b/75d9a713279796785711bd0bad8334aaace560c0bd28830c8c
Successfully built fbpca intervaltree
Installing collected packages: sortedcontainers, fbpca, intervaltree, geosketch, scanorama
Successfully installed fbpca-1.0 geosketch-1.3 intervaltree-3.1.0 scanorama-1.7.4 sortedcontainers-2.4.0
import scanorama
adata
AnnData object with n_obs × n_vars = 15476 × 13386
obs: 'Sample', 'n_counts', 'n_genes', 'batch', 'louvain', 'anno', 'Method', 'CellType', 'batch_id', 'n_genes_by_counts', 'log1p_n_genes_by_counts', 'total_counts', 'log1p_total_counts', 'pct_counts_in_top_50_genes', 'pct_counts_in_top_100_genes', 'pct_counts_in_top_200_genes', 'pct_counts_in_top_500_genes', 'leiden'
var: 'n_cells_by_counts', 'mean_counts', 'log1p_mean_counts', 'pct_dropout_by_counts', 'total_counts', 'log1p_total_counts', 'n_cells', 'highly_variable', 'means', 'dispersions', 'dispersions_norm'
uns: 'hvg', 'id_hvg', 'pca', 'neighbors_30', 'umap', 'leiden', 'batch_id_colors', 'leiden_colors'
obsm: 'X_pca', 'X_umap'
varm: 'PCs'
layers: 'raw_counts', 'norm_counts'
obsp: 'neighbors_30_distances', 'neighbors_30_connectivities'
First, we need to divide the data into respective batches.
# Our batch variable is stored under 'batch'
batch_id = 'batch'
adatas = []
for c in np.unique(adata.obs[batch_id]):
idx = adata.obs[batch_id] == c
adatas.append(adata[idx, :])
Now we can run Scanorama to obtain corrected expression counts.
corrected = scanorama.correct_scanpy(adatas,
return_dimred=True,
verbose=True,
dimred=30,
knn=30)
Found 13386 genes among all datasets
Processing datasets (0, 1)
/Users/sara.jimenez/miniconda3/envs/scvi-env/lib/python3.9/site-packages/scanorama/scanorama.py:237: FutureWarning: X.dtype being converted to np.float32 from float64. In the next version of anndata (0.9) conversion will not be automatic. Pass dtype explicitly to avoid this warning. Pass `AnnData(X, dtype=X.dtype, ...)` to get the future behavour.
adata = AnnData(datasets[i])
A note on the code above (you can also view the help page for scanorama):
The first input is a list of the adata, or batches we want to correct. Note: Scanorama directly acts on
.X.return_dimred = True implies that the method will return the reduced dimensions (like PCA) where the two batches have been co-embedded or co-aligned.
verbose = True indicates whether to output the intermediate comments.
dimred = 30 is the number of dimensions on which Scanorama will perform the cell nearest neighbor mathching. I set it to 30 because based on our analysis above, we find that 30 principal components capture enough variance.
knn = 30 is the number of nearest neighbors to estimate. This number should be smaller if you know the size of your sub-populations that are shared across batches is smaller.
Note: There is another parameter called hvg to specify the number of highly variable genes (automatically estimated by scanorama), which we welcome you to play with. The only catch is that if you specify this number, the output matrix will only be corrected with highly varying genes (i.e. not all the genes).
The output is stored in corrected which stores output anndata as lists. For example, corrected[0] contains the corrected data for batch-0 and corrected[1] contains the corrected data for batch-1.
corrected[0]
AnnData object with n_obs × n_vars = 8098 × 13386
obs: 'Sample', 'n_counts', 'n_genes', 'batch', 'louvain', 'anno', 'Method', 'CellType', 'batch_id', 'n_genes_by_counts', 'log1p_n_genes_by_counts', 'total_counts', 'log1p_total_counts', 'pct_counts_in_top_50_genes', 'pct_counts_in_top_100_genes', 'pct_counts_in_top_200_genes', 'pct_counts_in_top_500_genes', 'leiden'
var: 'n_cells_by_counts', 'mean_counts', 'log1p_mean_counts', 'pct_dropout_by_counts', 'total_counts', 'log1p_total_counts', 'n_cells', 'highly_variable', 'means', 'dispersions', 'dispersions_norm'
uns: 'hvg', 'id_hvg', 'pca', 'neighbors_30', 'umap', 'leiden', 'batch_id_colors', 'leiden_colors'
obsm: 'X_pca', 'X_umap', 'X_scanorama'
corrected[1]
AnnData object with n_obs × n_vars = 7378 × 13386
obs: 'Sample', 'n_counts', 'n_genes', 'batch', 'louvain', 'anno', 'Method', 'CellType', 'batch_id', 'n_genes_by_counts', 'log1p_n_genes_by_counts', 'total_counts', 'log1p_total_counts', 'pct_counts_in_top_50_genes', 'pct_counts_in_top_100_genes', 'pct_counts_in_top_200_genes', 'pct_counts_in_top_500_genes', 'leiden'
var: 'n_cells_by_counts', 'mean_counts', 'log1p_mean_counts', 'pct_dropout_by_counts', 'total_counts', 'log1p_total_counts', 'n_cells', 'highly_variable', 'means', 'dispersions', 'dispersions_norm'
uns: 'hvg', 'id_hvg', 'pca', 'neighbors_30', 'umap', 'leiden', 'batch_id_colors', 'leiden_colors'
obsm: 'X_pca', 'X_umap', 'X_scanorama'
We can combine the results and create a new anndata called adata_corrected.
adata_corrected = anndata.concat(corrected)
adata_corrected
AnnData object with n_obs × n_vars = 15476 × 13386
obs: 'Sample', 'n_counts', 'n_genes', 'batch', 'louvain', 'anno', 'Method', 'CellType', 'batch_id', 'n_genes_by_counts', 'log1p_n_genes_by_counts', 'total_counts', 'log1p_total_counts', 'pct_counts_in_top_50_genes', 'pct_counts_in_top_100_genes', 'pct_counts_in_top_200_genes', 'pct_counts_in_top_500_genes', 'leiden'
obsm: 'X_pca', 'X_umap', 'X_scanorama'
Note: In the above combined adata_corrected data, we have X_pca and X_umap, which were computed previously and should not used for the corrected combined data. So we need to recompute them. But first let’s save them as something else so they don’t overwritten.
adata_corrected.obsm['old_UMAP'] = adata_corrected.obsm['X_umap']
input_path
'/Users/sara.jimenez/Documents/scWorkshop/data/'
# Save for later:
adata_corrected.write_h5ad(input_path + 'processed/batch_data_scanorama_corrected.h5ad')
Nearest neighbors and UMAP#
Note: Corrected reduced dimensions - PCA analogous - have already been computed (they are stored in .obsm['X_scanorama']) so all we need to do is run nearest neighbors algorithm followed by UMAP for visualization.
# Nearest neighbors on corrected PCA
sc.pp.neighbors(adata_corrected, n_neighbors=30, use_rep='X_scanorama', metric='euclidean',
key_added='neighbors_30_corrected')
# UMAP, FDL using the nearest neighbors
sc.tl.umap(adata_corrected, neighbors_key = 'neighbors_30_corrected', min_dist=0.1)
Visualize#
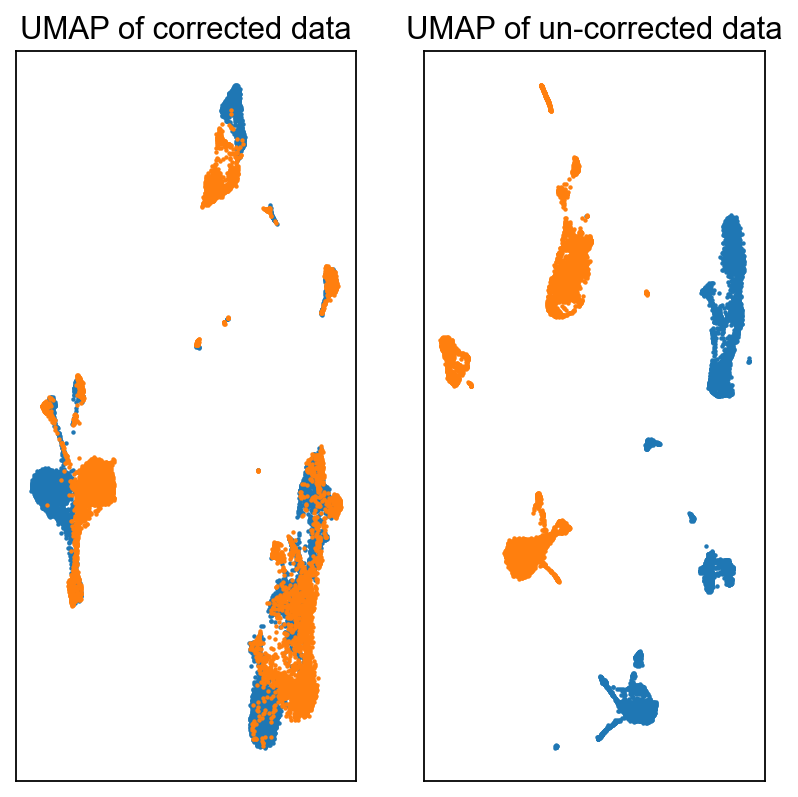
fig = plt.figure(figsize = (3*2, 3*2))
ax = fig.add_subplot(1, 2, 1)
c0 = adata_corrected.obs['batch'].astype(int) == 0
c1 = adata_corrected.obs['batch'].astype(int) == 1
ax.scatter(adata_corrected.obsm['X_umap'][c0, 0], adata_corrected.obsm['X_umap'][c0, 1], s = 1, label = 'Batch-0')
ax.scatter(adata_corrected.obsm['X_umap'][c1, 0], adata_corrected.obsm['X_umap'][c1, 1], s = 1, label = 'Batch-1')
ax.set_xticks([])
ax.set_yticks([])
ax.set_title('UMAP of corrected data')
ax = fig.add_subplot(1, 2, 2)
c0 = adata.obs['batch'] == 0
c1 = adata.obs['batch'] == 1
ax.scatter(adata_corrected.obsm['old_UMAP'][c0, 0], adata_corrected.obsm['old_UMAP'][c0, 1], s = 1, label = 'Batch-0')
ax.scatter(adata_corrected.obsm['old_UMAP'][c1, 0], adata_corrected.obsm['old_UMAP'][c1, 1], s = 1, label = 'Batch-1')
ax.set_xticks([])
ax.set_yticks([])
ax.set_title('UMAP of un-corrected data')
Text(0.5, 1.0, 'UMAP of un-corrected data')
help(scanorama.correct)
Help on function correct in module scanorama.scanorama:
correct(datasets_full, genes_list, return_dimred=False, batch_size=5000, verbose=2, ds_names=None, dimred=100, approx=True, sigma=15, alpha=0.1, knn=20, return_dense=False, hvg=None, union=False, seed=0)
Integrate and batch correct a list of data sets.
Parameters
----------
datasets_full : `list` of `scipy.sparse.csr_matrix` or of `numpy.ndarray`
Data sets to integrate and correct.
genes_list: `list` of `list` of `string`
List of genes for each data set.
return_dimred: `bool`, optional (default: `False`)
In addition to returning batch corrected matrices, also returns
integrated low-dimesional embeddings.
batch_size: `int`, optional (default: `5000`)
The batch size used in the alignment vector computation. Useful when
correcting very large (>100k samples) data sets. Set to large value
that runs within available memory.
verbose: `bool` or `int`, optional (default: 2)
When `True` or not equal to 0, prints logging output.
ds_names: `list` of `string`, optional
When `verbose=True`, reports data set names in logging output.
dimred: `int`, optional (default: 100)
Dimensionality of integrated embedding.
approx: `bool`, optional (default: `True`)
Use approximate nearest neighbors, greatly speeds up matching runtime.
sigma: `float`, optional (default: 15)
Correction smoothing parameter on Gaussian kernel.
alpha: `float`, optional (default: 0.10)
Alignment score minimum cutoff.
knn: `int`, optional (default: 20)
Number of nearest neighbors to use for matching.
return_dense: `bool`, optional (default: `False`)
Return `numpy.ndarray` matrices instead of `scipy.sparse.csr_matrix`.
hvg: `int`, optional (default: None)
Use this number of top highly variable genes based on dispersion.
seed: `int`, optional (default: 0)
Random seed to use.
Returns
-------
corrected, genes
By default (`return_dimred=False`), returns a two-tuple containing a
list of `scipy.sparse.csr_matrix` each with batch corrected values,
and a single list of genes containing the intersection of inputted
genes.
integrated, corrected, genes
When `return_dimred=True`, returns a three-tuple containing a list
of `numpy.ndarray` with integrated low dimensional embeddings, a list
of `scipy.sparse.csr_matrix` each with batch corrected values, and a
a single list of genes containing the intersection of inputted genes.
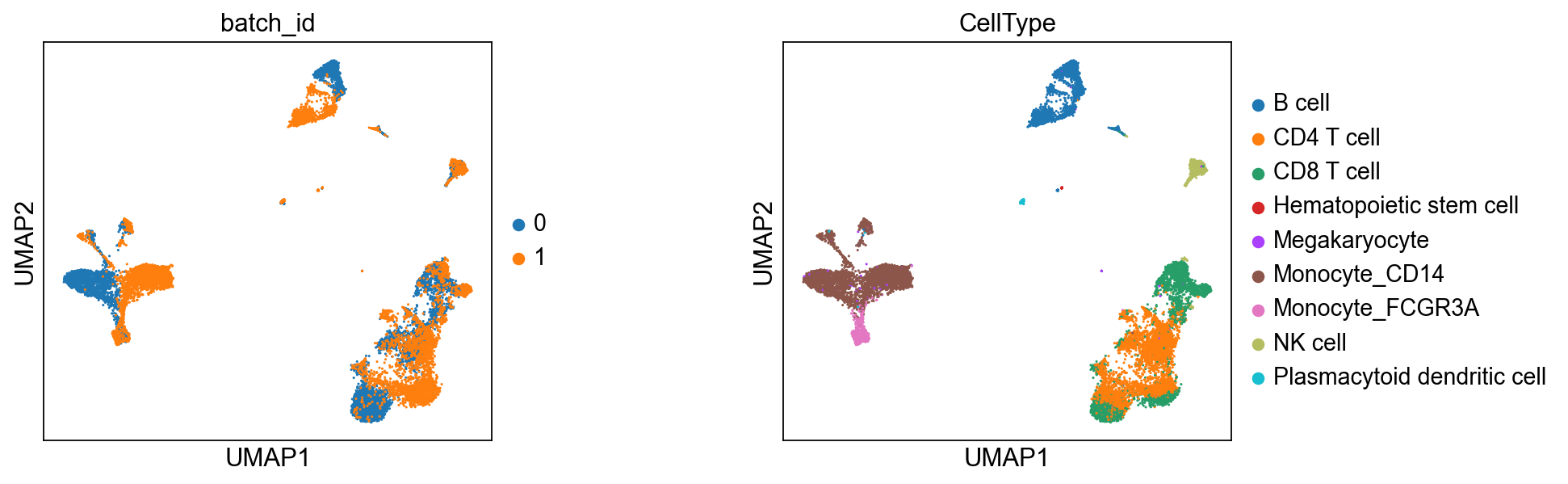
True celltypes#
sc.pl.umap(adata_corrected, color = ['batch_id', 'CellType'], wspace=0.5)
/Users/sara.jimenez/miniconda3/envs/scvi-env/lib/python3.9/site-packages/scanpy/plotting/_tools/scatterplots.py:392: UserWarning: No data for colormapping provided via 'c'. Parameters 'cmap' will be ignored
cax = scatter(
/Users/sara.jimenez/miniconda3/envs/scvi-env/lib/python3.9/site-packages/scanpy/plotting/_tools/scatterplots.py:392: UserWarning: No data for colormapping provided via 'c'. Parameters 'cmap' will be ignored
cax = scatter(
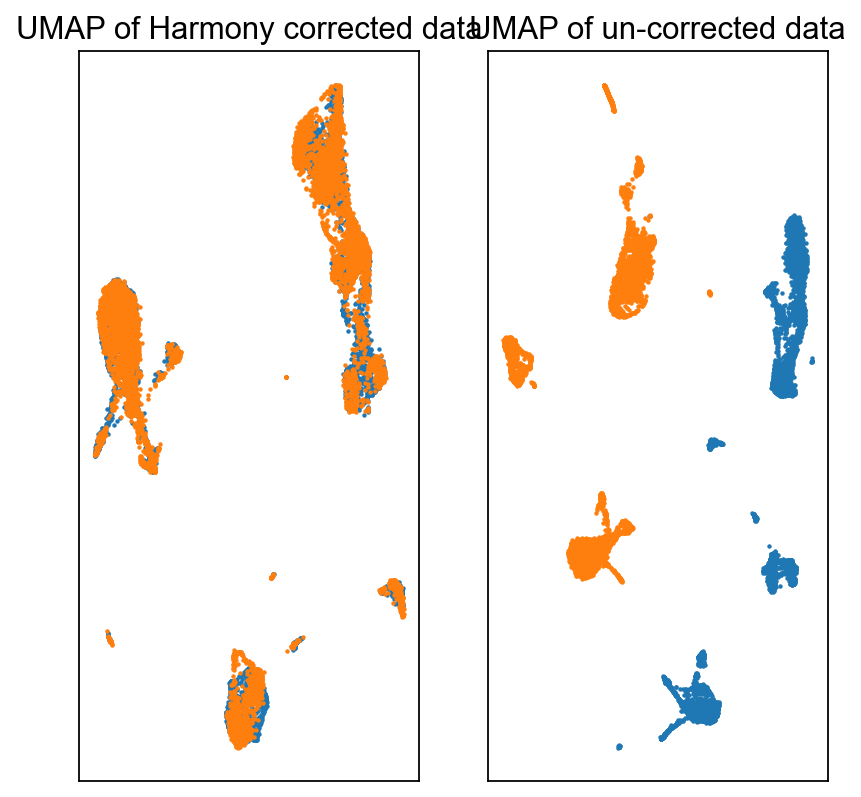
Batch effect correction - Harmony#
Harmony is another popular method for correcting batch effect in single-cell RNA-sequencing data. As discussed in the beginning, Harmony iteratively removes batch effects in the PCA space. In each iteration, it clusters similar cells from different batches and maximizing the diversity of batches within each cluster; it then calculates a correction factor for each cell to be applied. While it is a fast method, there are a couple caveats: 1) Since it operates only on the PCA space, any non-linear association between features could be missed or altered; and 2) Harmony does not provide a corrected gene expression matrix. Therefore, the output of Harmony can only be used for visualization and clustering but not for differential expression analysis or any gene centric analysis, since one does not get a corrected expression matrix back. One would need to be careful to perform downstream analysis with Harmony.
Harmony is implemented in Scanpy: https://scanpy.readthedocs.io/en/stable/generated/scanpy.external.pp.harmony_integrate.html.
Let’s first make a copy of adata for application of Harmony. Note we do not simply do adata_harmony = adata but specify adata_harmony = adata.copy() because of the issue of mutable variables in Python. See more here: https://www.geeksforgeeks.org/mutable-vs-immutable-objects-in-python/
adata_harmony = adata.copy()
# Please run this step if we did not install harmonypy
!pip install harmonypy
Collecting harmonypy
Downloading harmonypy-0.0.10-py3-none-any.whl (20 kB)
Requirement already satisfied: pandas in /Users/sara.jimenez/miniconda3/envs/scvi-env/lib/python3.9/site-packages (from harmonypy) (1.5.3)
Requirement already satisfied: scipy in /Users/sara.jimenez/miniconda3/envs/scvi-env/lib/python3.9/site-packages (from harmonypy) (1.11.4)
Requirement already satisfied: numpy in /Users/sara.jimenez/miniconda3/envs/scvi-env/lib/python3.9/site-packages (from harmonypy) (1.26.4)
Requirement already satisfied: scikit-learn in /Users/sara.jimenez/miniconda3/envs/scvi-env/lib/python3.9/site-packages (from harmonypy) (1.2.2)
Requirement already satisfied: python-dateutil>=2.8.1 in /Users/sara.jimenez/miniconda3/envs/scvi-env/lib/python3.9/site-packages (from pandas->harmonypy) (2.8.2)
Requirement already satisfied: pytz>=2020.1 in /Users/sara.jimenez/miniconda3/envs/scvi-env/lib/python3.9/site-packages (from pandas->harmonypy) (2023.3)
Requirement already satisfied: joblib>=1.1.1 in /Users/sara.jimenez/miniconda3/envs/scvi-env/lib/python3.9/site-packages (from scikit-learn->harmonypy) (1.2.0)
Requirement already satisfied: threadpoolctl>=2.0.0 in /Users/sara.jimenez/miniconda3/envs/scvi-env/lib/python3.9/site-packages (from scikit-learn->harmonypy) (3.1.0)
Requirement already satisfied: six>=1.5 in /Users/sara.jimenez/miniconda3/envs/scvi-env/lib/python3.9/site-packages (from python-dateutil>=2.8.1->pandas->harmonypy) (1.16.0)
Installing collected packages: harmonypy
Successfully installed harmonypy-0.0.10
sc.external.pp.harmony_integrate(adata_harmony,
key = 'batch_id',
basis='X_pca',
adjusted_basis='X_pca_harmony')
2024-11-08 00:24:58,334 - harmonypy - INFO - Computing initial centroids with sklearn.KMeans...
2024-11-08 00:25:01,665 - harmonypy - INFO - sklearn.KMeans initialization complete.
2024-11-08 00:25:01,729 - harmonypy - INFO - Iteration 1 of 10
2024-11-08 00:25:04,518 - harmonypy - INFO - Iteration 2 of 10
2024-11-08 00:25:10,266 - harmonypy - INFO - Iteration 3 of 10
2024-11-08 00:25:18,058 - harmonypy - INFO - Iteration 4 of 10
2024-11-08 00:25:25,918 - harmonypy - INFO - Iteration 5 of 10
2024-11-08 00:25:33,910 - harmonypy - INFO - Iteration 6 of 10
2024-11-08 00:25:41,468 - harmonypy - INFO - Iteration 7 of 10
2024-11-08 00:25:50,139 - harmonypy - INFO - Iteration 8 of 10
2024-11-08 00:25:57,992 - harmonypy - INFO - Iteration 9 of 10
2024-11-08 00:26:00,988 - harmonypy - INFO - Converged after 9 iterations
adata_harmony
AnnData object with n_obs × n_vars = 15476 × 13386
obs: 'Sample', 'n_counts', 'n_genes', 'batch', 'louvain', 'anno', 'Method', 'CellType', 'batch_id', 'n_genes_by_counts', 'log1p_n_genes_by_counts', 'total_counts', 'log1p_total_counts', 'pct_counts_in_top_50_genes', 'pct_counts_in_top_100_genes', 'pct_counts_in_top_200_genes', 'pct_counts_in_top_500_genes', 'leiden'
var: 'n_cells_by_counts', 'mean_counts', 'log1p_mean_counts', 'pct_dropout_by_counts', 'total_counts', 'log1p_total_counts', 'n_cells', 'highly_variable', 'means', 'dispersions', 'dispersions_norm'
uns: 'hvg', 'id_hvg', 'pca', 'neighbors_30', 'umap', 'leiden', 'batch_id_colors', 'leiden_colors'
obsm: 'X_pca', 'X_umap', 'X_pca_harmony'
varm: 'PCs'
layers: 'raw_counts', 'norm_counts'
obsp: 'neighbors_30_distances', 'neighbors_30_connectivities'
Now we just need to recompute the neighbors and UMAP on the above computed X_pca_harmony:
# Save to prevent overwriting
adata_harmony.obsm['old_UMAP'] = adata_harmony.obsm['X_umap']
# Nearest neighbors on PCA_harmony
sc.pp.neighbors(adata_harmony, n_neighbors=30, use_rep='X_pca_harmony', metric='euclidean',
key_added='neighbors_30_harmony')
# UMAP using the nearest neighbors
sc.tl.umap(adata_harmony, neighbors_key = 'neighbors_30_harmony', min_dist=0.1)
fig = plt.figure(figsize = (3*2, 3*2))
ax = fig.add_subplot(1, 2, 1)
c0 = adata_harmony.obs['batch'].astype(int) == 0
c1 = adata_harmony.obs['batch'].astype(int) == 1
ax.scatter(adata_harmony.obsm['X_umap'][c0, 0], adata_harmony.obsm['X_umap'][c0, 1], s = 1, label = 'Batch-0')
ax.scatter(adata_harmony.obsm['X_umap'][c1, 0], adata_harmony.obsm['X_umap'][c1, 1], s = 1, label = 'Batch-1')
ax.set_xticks([])
ax.set_yticks([])
ax.set_title('UMAP of Harmony corrected data')
ax = fig.add_subplot(1, 2, 2)
c0 = adata.obs['batch'] == 0
c1 = adata.obs['batch'] == 1
ax.scatter(adata_harmony.obsm['old_UMAP'][c0, 0], adata_harmony.obsm['old_UMAP'][c0, 1], s = 1, label = 'Batch-0')
ax.scatter(adata_harmony.obsm['old_UMAP'][c1, 0], adata_harmony.obsm['old_UMAP'][c1, 1], s = 1, label = 'Batch-1')
ax.set_xticks([])
ax.set_yticks([])
ax.set_title('UMAP of un-corrected data')
Text(0.5, 1.0, 'UMAP of un-corrected data')
sc.pl.umap(adata_harmony, color = ['CellType'])
/Users/sara.jimenez/miniconda3/envs/scvi-env/lib/python3.9/site-packages/scanpy/plotting/_tools/scatterplots.py:392: UserWarning: No data for colormapping provided via 'c'. Parameters 'cmap' will be ignored
cax = scatter(
